Model HQ
DocumentationHybrid Inferencing using Model HQ (AI PC + API Server)
Seamlessly combine local and server-based inference modes for maximum flexibility
Goal
Seamlessly combine local and server-based inference modes—chat, agents, and semantic search—all from one interface.
This walkthrough is built for developers or technical practitioners looking to toggle between local AI PC inferencing and API server-based inference, including how to access remote vector libraries, run agents remotely, and build enterprise-wide RAG pipelines.
Video Tutorial Available
This walkthrough is also demonstrated step-by-step on our YouTube video:
"Unlock Hybrid AI: AI PC + API Server"Requirements
| Tool | Purpose |
|---|---|
| Model HQ (on AI PC) | Run local inference and manage flows |
| Model HQ API Server | Run inference remotely; host vector DB |
| Vector DB | Store document embeddings (included in Model HQ) |
| Sample PDFs/Text Docs | Created from source material included with Model HQ |
Model HQ (on AI PC)
Run local inference and manage flows
Model HQ API Server
Run inference remotely; host vector DB
Vector DB
Store document embeddings (included in Model HQ)
Sample PDFs/Text Docs
Created from source material included with Model HQ
Step-by-Step Process
Connect Model HQ Desktop to the API Server
1.1 Launch the Model HQ App on your AI PC
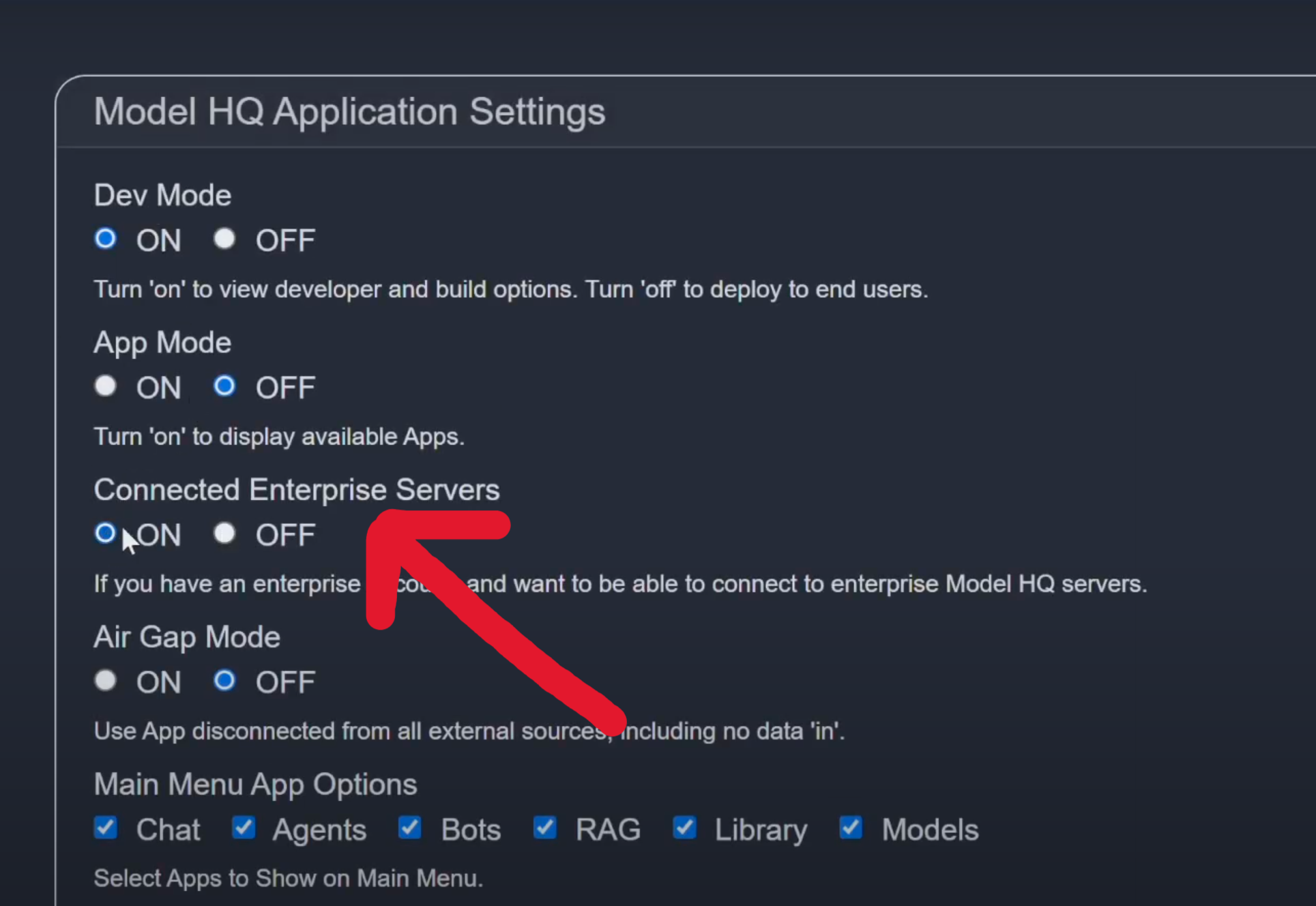
- 1Ensure your AI PC is network-accessible to the API server
- 2Select the Configure button on the top right of the app
- 3Go to App in the Model HQ Configuration Center
- 4Toggle Connected Enterprise Servers to ON
- 5Click
>at the bottom of the screen
Note
If you do not have an API connection pre-established, you will be directed to the 'Add New API Connection' screen, where you can enter the API Name, IP Address, Port and Secret Key information to establish a connection.
1.2 Confirm Server Discoverability
- When connected, a Library button appears on the Main Menu bar

This unlocks access to:
- Chats and agents locally or through API
- Vector search libraries hosted on the API server
- Remote model options (e.g., larger LLMs)
- Server-side agents
Run Chat Inference Locally or via Server
2.1 Start a New Chatbot Session
- 1From the Main Menu, go to Bots
- 2You'll see local bots like Fast Start Chatbot or Model HQ Biz Bot
- 3You'll also see server-based bots like Model HQ API Server Biz Bot
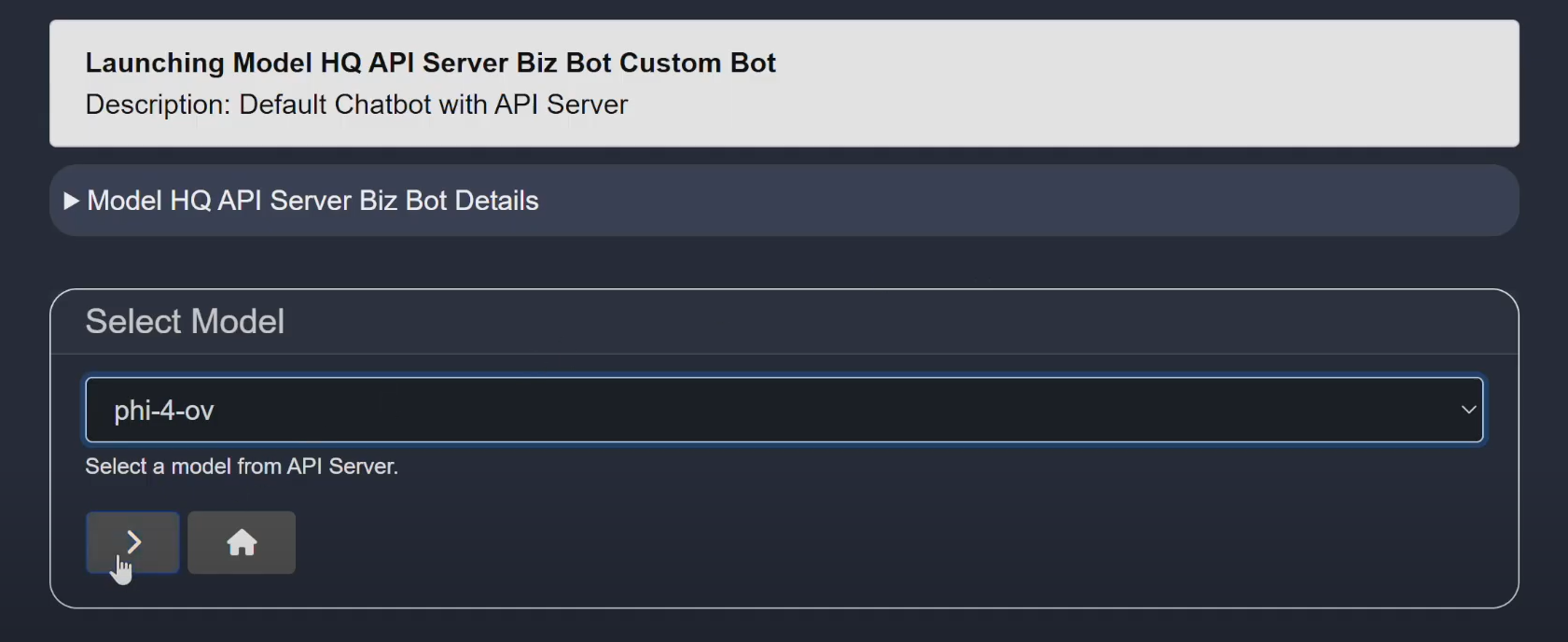
- 4Select the Model HQ
API Server Biz Botand click> - 5Choose a model (e.g., Phi-4-ov) running on the server
- 6Begin chatting with the model
2.2 What Happens Behind the Scenes
Local Mode
Query processed by local model (e.g., 7B)
Server Mode
Request sent over API to Model HQ Server
- Can be hosted on cloud, datacenter, or office server
- Example: 14B parameter model
- Response is returned and shown in chat
Use Remote Knowledge with Local Inference (Hybrid RAG)
3.1 Start a Local Chat Session
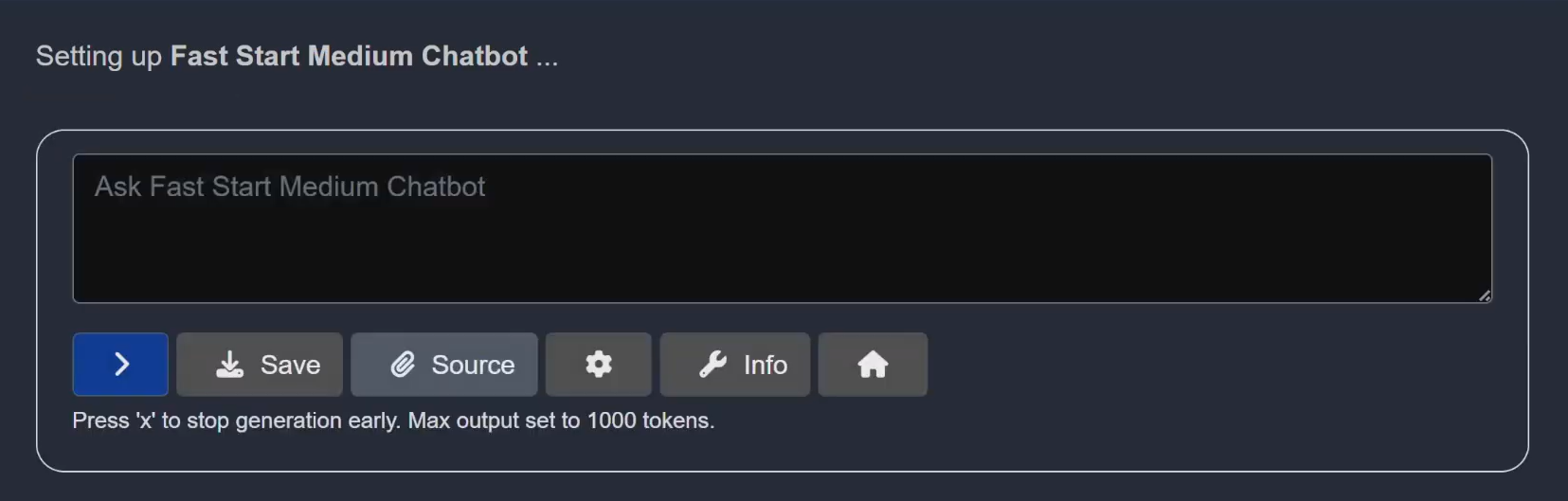
- 1From the Main Menu, select Chat
- 2Choose Medium (7B) – Analysis and Typical RAG, then click
>
3.2 Connect to Remote Knowledge Base
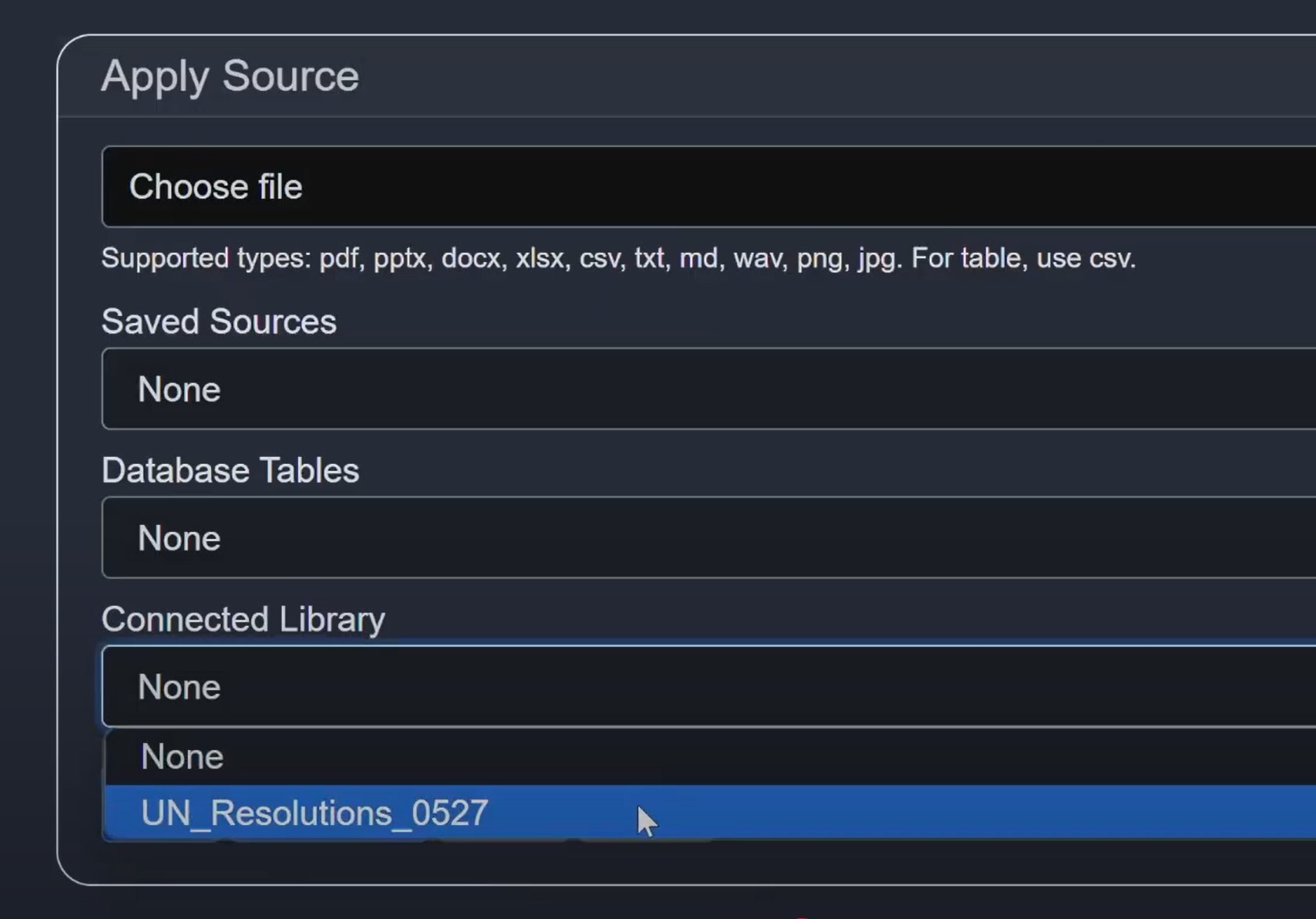
- 1Once chatbot is open, click Source
- 2Select a server-hosted library (e.g.,
UN_Resolutions_0527)If no pre-created source exists, follow Step 5 to build one
3.3 Enter a RAG-style Question
Example:
"What are the resolutions related to Ukraine?"
3.4 What Happens
- Vector search is executed on the API server
- Retrieved documents are returned to your AI PC
- Local model performs inference over those chunks
You see:
- Full source references
- Answer generated on-device
- No tokens leave your machine

Run Agent Workflows on the API Server
4.1 Choose a Prebuilt or Custom Agent
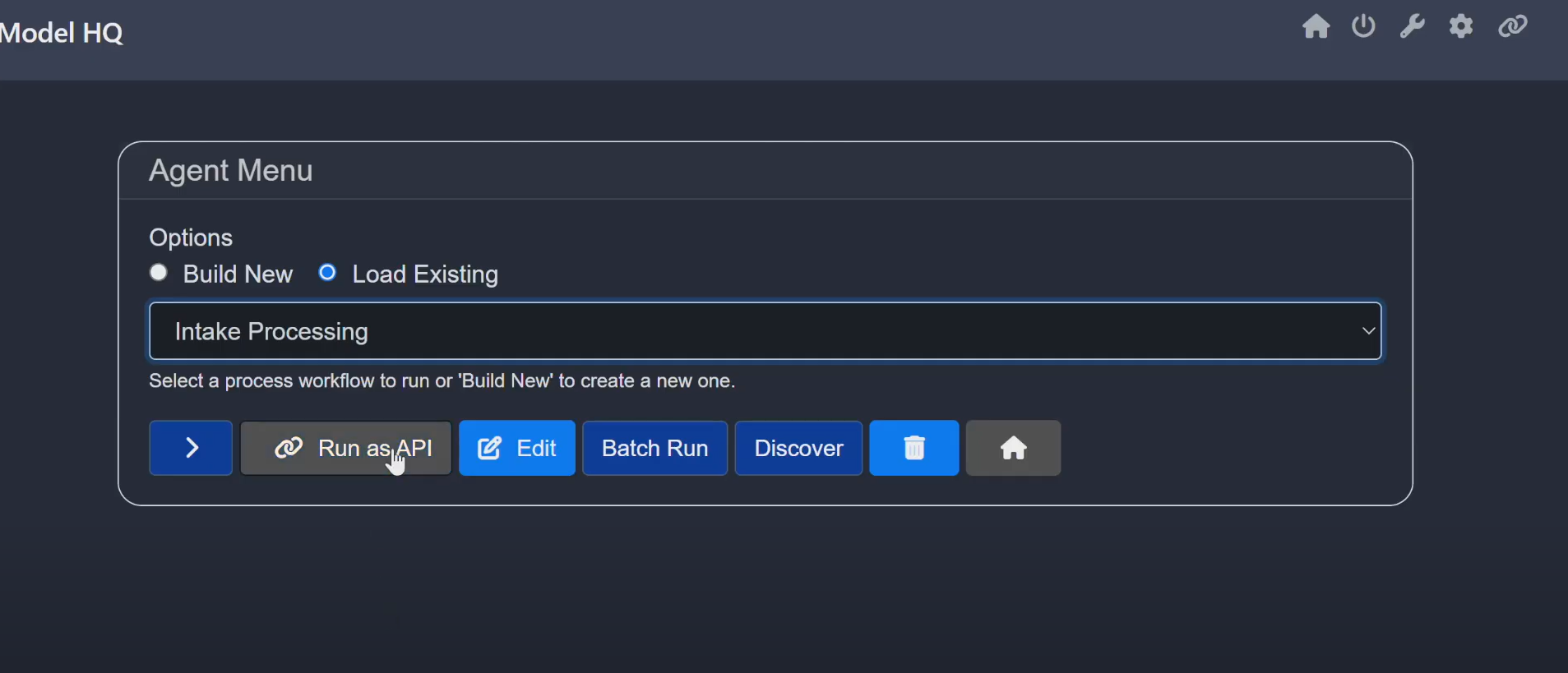
- 1From the Main Menu, go to Agents
- 2Select Intake Processing, then click Run as API
4.2 Provide Input
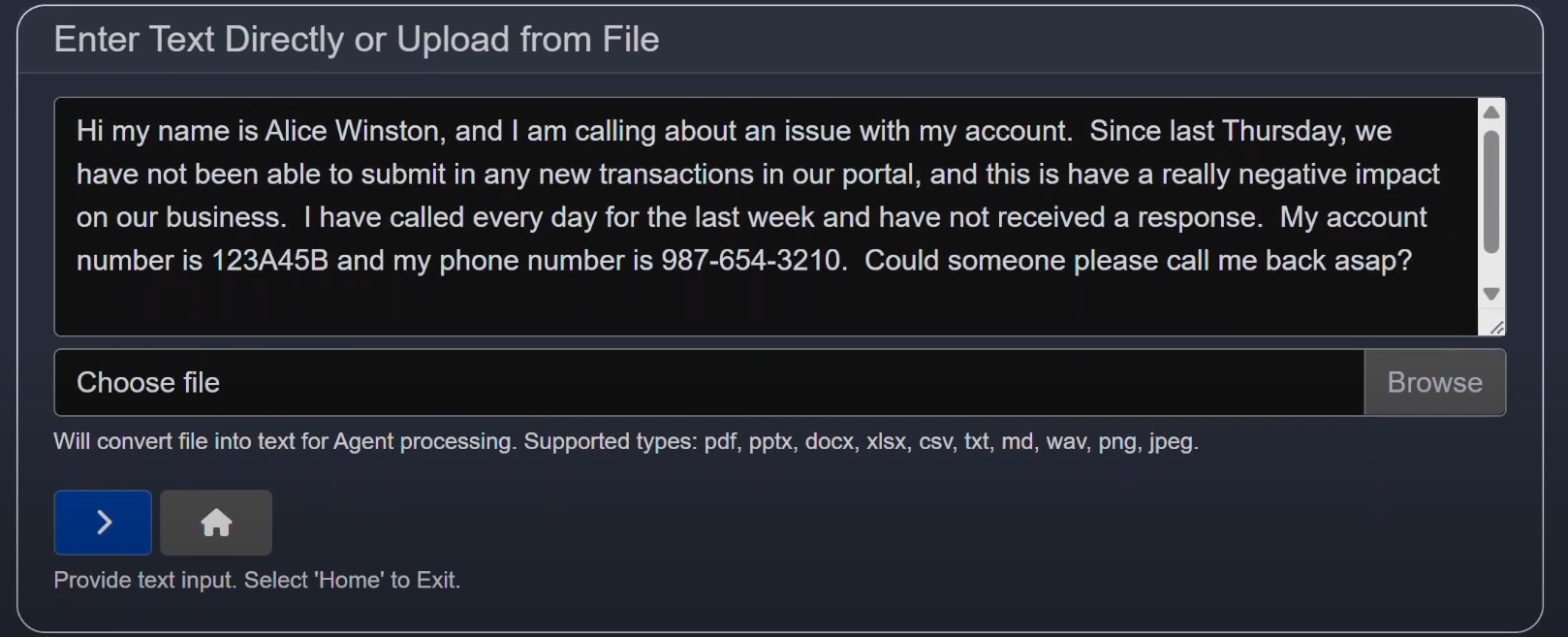
- 1On the input screen, click Choose File
- 2Select:
C:\Users\[username]\llmware_data\sample_files\customer_transcripts\customer_transcript_1.txt - 3Click
>, confirm input appears, then continue
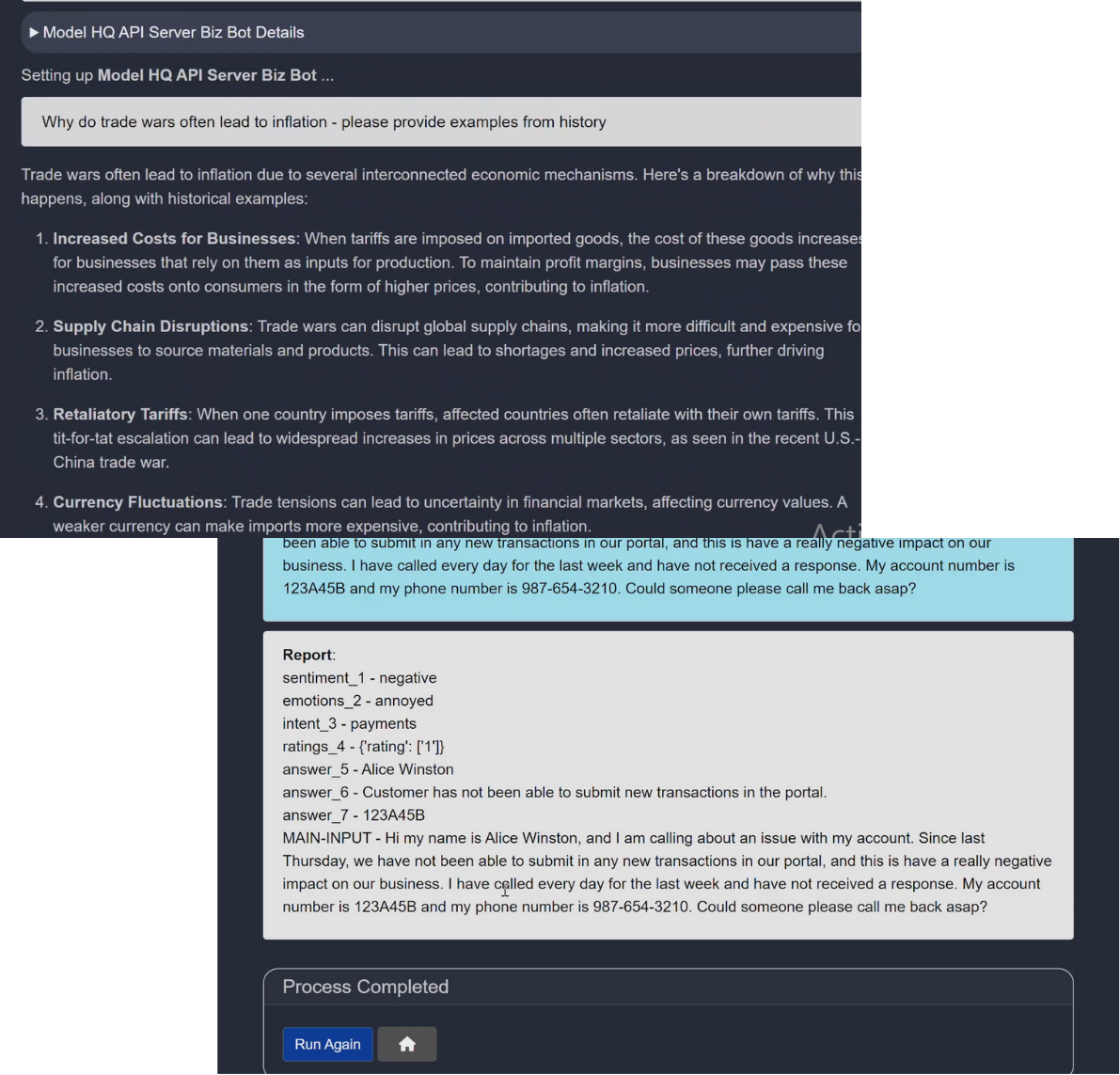
4.3 What Happens
- Agent process and input are sent over API
- Agent runs fully on the API Server
- Results are returned to the AI PC and displayed
Build a Shared Semantic Library with Vector DB
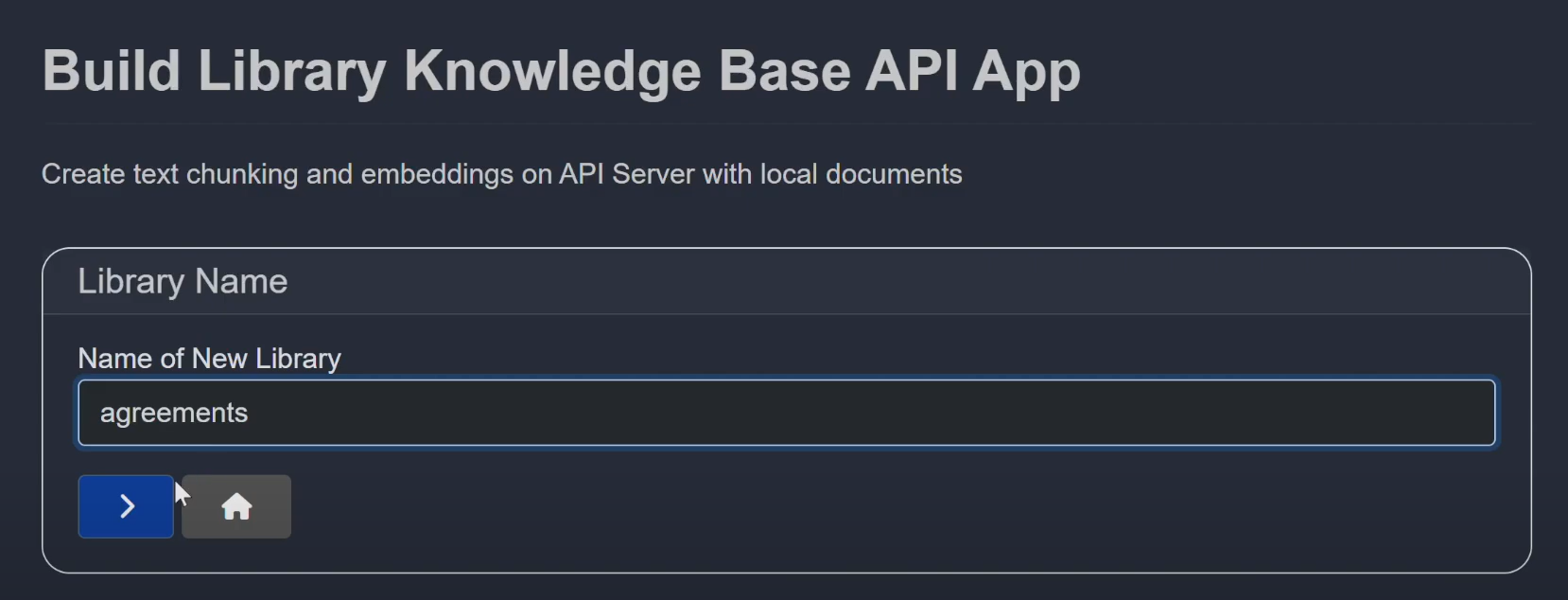
5.1 Create a New Library
- 1Click Library from the Main Menu
- 2Select Build New
- 3Name your library (e.g., agreements)
5.2 Upload Source Files
- 1Click +Add Files
- 2Choose ~20 PDFs from:
C:\Users\[username]\llmware_data\sample_files\UN-Resolutions-500 - 3Select Done
- 4Files are sent to the API server
5.3 Configure Embedding Settings
- 1Go to:Library Actions → Library → [your library name]
- 2Click Create Embedding
5.4 Trigger Embedding
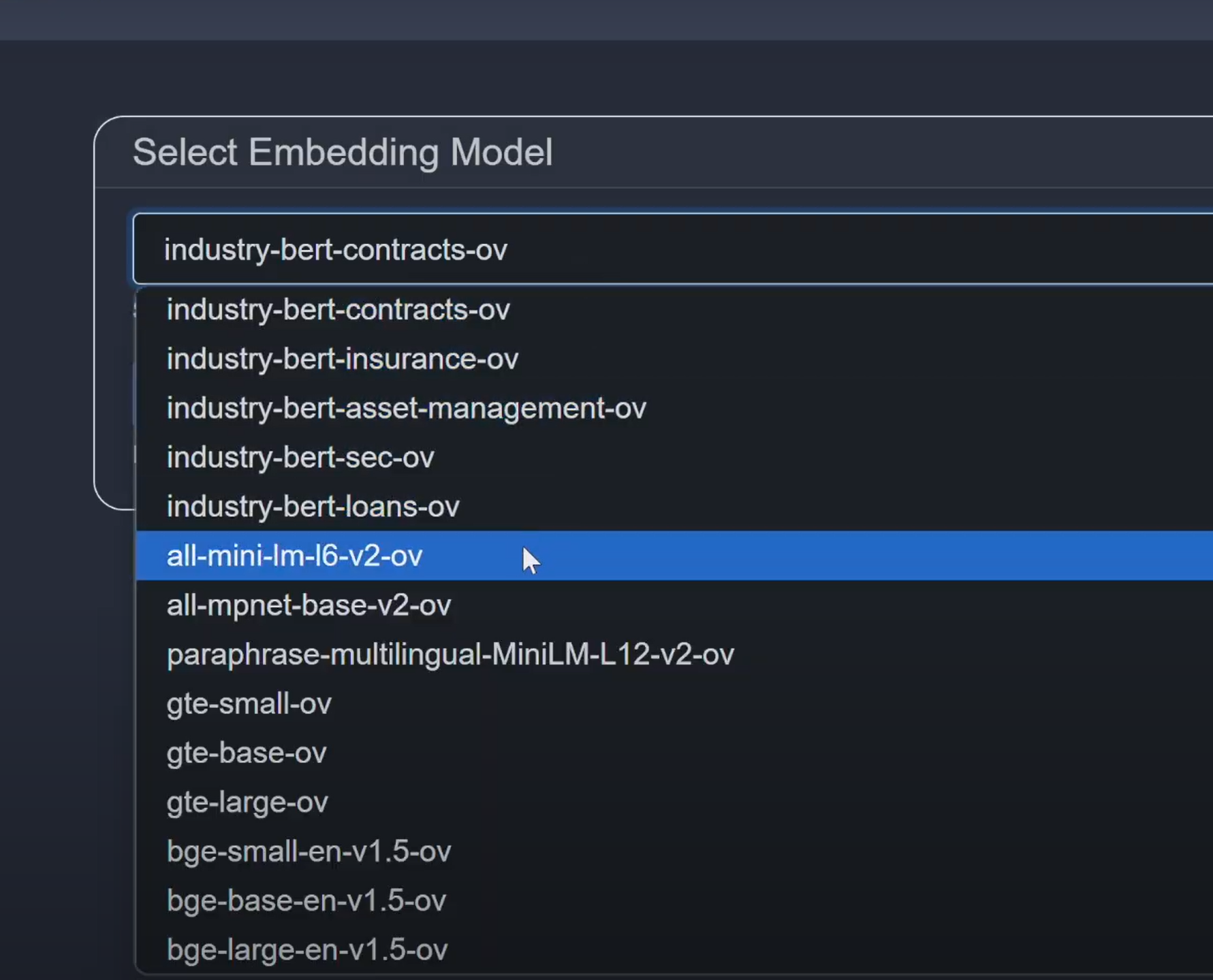
- 1Select an embedding model (e.g., all-mini-lm-l6-v2-ov)
- 2Click
>to start embedding process
Model HQ will:
- Parse and chunk documents
- Create embeddings
- Store them in the server-hosted vector DB
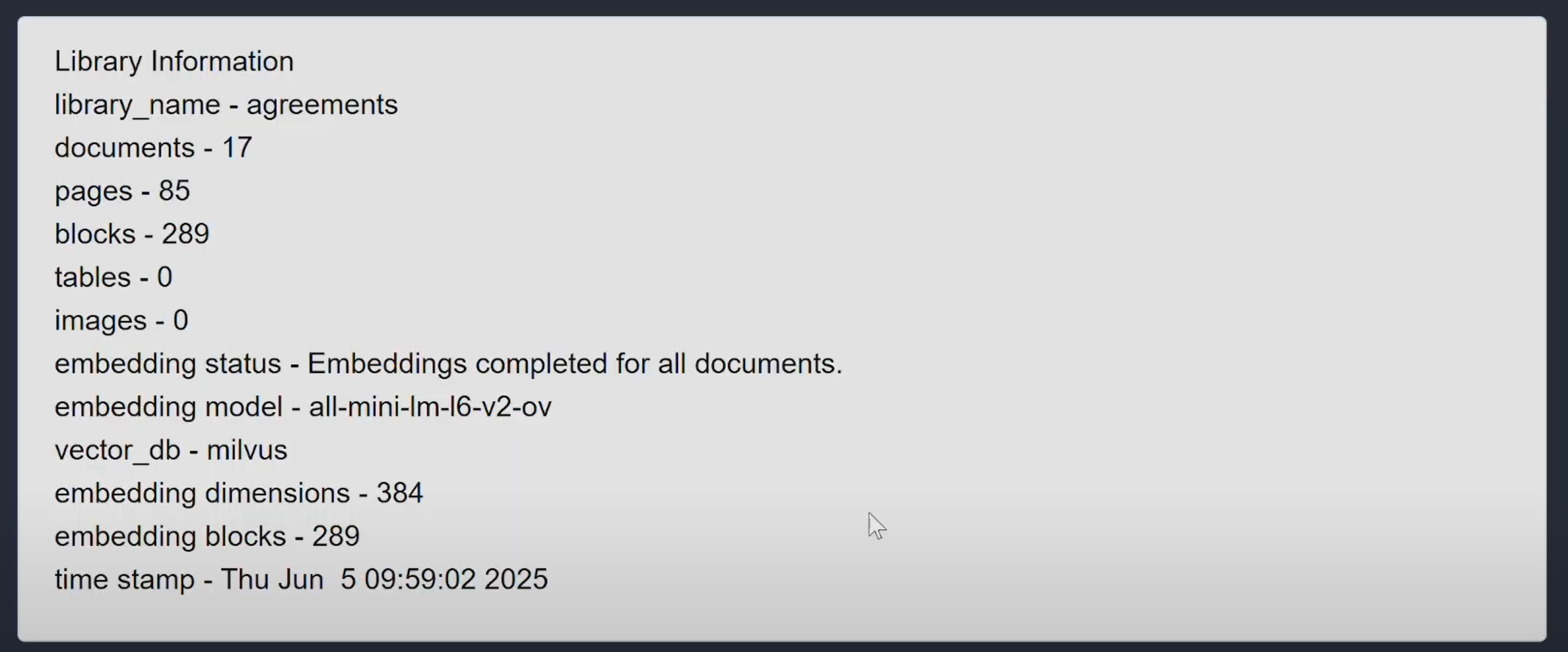
Once complete, you'll see the library info and embeddings summary.
5.5 What You Now Have
- A shareable, queryable knowledge base
- Indexed and hosted on the API server
- Accessible to any Model HQ user connected to the server
Use That Library in Any Chat or Agent Flow
6.1 Return to Chat
- 1Open a local or server-run chat
- 2In Sources, select your newly created vector library
6.2 Ask Questions
- Type natural-language queries related to your document domain
6.3 See Results
- Vector search occurs remotely
- Context is retrieved
- Inference runs locally or on the server (your choice)
Summary: Hybrid Modes You Can Mix and Match
| Pattern | Vector Search | Inference | Trigger From |
|---|---|---|---|
| Local-Only | Local files | AI PC | Desktop |
| Server-Only | Server KB | API Server | Desktop |
| Hybrid RAG | Server KB | AI PC | Desktop |
| Remote Agent | N/A or Server | API Server | Desktop |
| Full API | All remote | API Server | External app |
Local-Only
Server-Only
Hybrid RAG
Remote Agent
Full API
Pro Tips
Privacy & Offline Access
Use local inference when privacy or offline access is important
Scale & Performance
Use server inference for larger models or batch processing
Team Collaboration
Build shared vector libraries for team-wide semantic search
Easy Configuration
All toggles and source configurations are available in a single UI—no CLI required
Need Help?
If you encounter any issues while setting up hybrid inferencing, feel free to contact our support team at support@aibloks.com.